
Monitorare le performance di un server Linux – o più specificatamente un server, ad esempio – è uno dei target principali di ogni buon amministratore di rete: del resto questo sistema operativo, nelle sue varie distribuzioni, offre moltissimi tool gratuiti per farlo, i quali possono essere utilizzati per ottenere informazioni di vario genere. I vari problemi in cui potreste imbattervi possono essere rilevati, ed in certi casi risolti, dall’uso di questo strumenti a linea di comando (terminale).
Quelli che abbiamo elencato in questo articolo sono annessi a:
- rilevamento di “colli di bottiglia” del sistema;
- rilevamento di “colli di bottiglia” che rallentano il disco;
- rilevamento di “colli di bottiglia” che rallentano la CPU e la RAM;
- rilevamento di “colli di bottiglia” che rallentano la rete.
1) Comando “top”
top
Aprite una finestra del terminale e digitate top: comparirà una finestra come quella mostrata di seguito nella quale sarà possibile vedere, in tempo reale, i processi attivi, il consumo di CPU di ognuno di essi e così via. Nel caso in esame abbiamo 108 processi in memoria di cui 3 attivi, 1 bloccato, 104 temporaneamente fermi ed un totale di 595 thread; la CPU viene utilizzata all’11,29%, mentre nelle righe successive sono indicati gli utilizzi di memoria, Virtual Machine e rete.
Processes: 108 total, 3 running, 1 stuck, 104 sleeping, 595 threads 12:07:36 Load Avg: 1.14, 1.10, 1.01 CPU usage: 11.29% user, 6.22% sys, 82.48% idle SharedLibs: 1076K resident, 0B data, 0B linkedit. MemRegions: 46363 total, 1127M resident, 70M private, 568M shared. PhysMem: 1081M wired, 1590M active, 831M inactive, 3502M used, 591M free. VM: 226G vsize, 1026M framework vsize, 178681(125) pageins, 0(0) pageouts. Networks: packets: 287864/292M in, 230626/32M out. Disks: 38719/2294M read, 74189/2652M written. PID COMMAND %CPU TIME #TH #WQ #POR #MREGS RPRVT RSHRD RSIZE VPRVT VSIZE PGRP 424 top 7.4 00:00.73 1/1 0 24 30 1072K 216K 1820K 17M 2376M 424 423 mdworker 0.0 00:00.08 3 1 55 69 3268K 4376K 7848K 52M 2414M 423 418 bash 0.0 00:00.01 1 0 21 25 400K 216K 1208K 17M 2376M 418 417 CVMCompiler 5.4 00:00.19 3 3 37+ 77+ 13M+ 228K 23M+ 58M+ 2435M+ 417 416 login 0.0 00:00.06 2 1 33 67 1048K 236K 4728K 50M 2409M 416 411 xpcd 0.0 00:00.05 2 2 35 58 828K 248K 4520K 51M 2410M 411 410 com.dev.sp 0.0 00:00.05 2 2 31 53 628K 212K 4380K 51M 2409M 410 409 com.dev.iC 0.0 00:00.19 3 1 53 64 1244K 3244K 5720K 51M 2428M 409 408 ocspd 0.0 00:00.04 1 0 22 33 760K 272K 2236K 44M 2403M 408 404 quicklookd 0.0 00:00.43 4 1 78 95 6096K 5720K 12M 64M 2944M 404 403 taskgated 0.0 00:00.05 2 1 28 58 964K 3260K 2920K 47M 2424M 403 358 com.dev.au 0.0 00:00.03 2 2 32 55 756K 216K 4424K 51M 2409M 358 357 xpcd 0.0 00:00.08 2 2 36 59 1100K 248K 4780K 51M 2410M 357 346 pbs 0.0 00:00.56 4 4 52 59 2500K 2288K 4352K 51M 2411M
2) Comando “vmstat”
vmstat 3
vmstat fornisce informazioni dettagliate su processi, uso della memoria, paginazione, I/O, trap ed attività della CPU.
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 2540988 522188 5130400 0 0 2 32 4 2 4 1 96 0 0 1 0 0 2540988 522188 5130400 0 0 0 720 1199 665 1 0 99 0 0 0 0 0 2540956 522188 5130400 0 0 0 0 1151 1569 4 1 95 0 0 0 0 0 2540956 522188 5130500 0 0 0 6 1117 439 1 0 99 0 0 0 0 0 2540940 522188 5130512 0 0 0 536 1189 932 1 0 98 0 0 0 0 0 2538444 522188 5130588 0 0 0 0 1187 1417 4 1 96 0 0 0 0 0 2490060 522188 5130640 0 0 0 18 1253 1123 5 1 94 0 0
Due possibili varianti riguardo la possibilità di mostrare soltanto l’utilizzo della memoria :
vmstat -m
e quello dei vari processi attivi/non attivi:
vmstat -a
3) Comando “w”
w username
w (con eventuale parametro username corrispondente all’utenza di cui vogliamo saperne di più) mostra informazioni sugli utenti connessi al sistema e sulla loro attività, ad esempio:
w
senza parametri mostra informazioni sugli utenti attivi sulla macchina e sui processi a cui hanno accesso in quel momento:
17:58:47 up 5 days, 20:28, 2 users, load average: 0.36, 0.26, 0.24 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root pts/0 10.1.3.145 14:55 5.00s 0.04s 0.02s vim /etc/resolv.conf root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
4) Comando “uptime”
uptime
uptime mostra il periodo di attività del server a partire dal suo avvio:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
5) Comando “ps”
ps -A
ps mostra una snapshot delle attività correnti del sistema:
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:02 migration/0
3 ? 00:00:01 ksoftirqd/0
4 ? 00:00:00 watchdog/0
5 ? 00:00:00 migration/1
6 ? 00:00:15 ksoftirqd/1
....
.....
4881 ? 00:53:28 java
4885 tty1 00:00:00 mingetty
4886 tty2 00:00:00 mingetty
4887 tty3 00:00:00 mingetty
4888 tty4 00:00:00 mingetty
4891 tty5 00:00:00 mingetty
4892 tty6 00:00:00 mingetty
4893 ttyS1 00:00:00 agetty
12853 ? 00:00:00 cifsoplockd
12854 ? 00:00:00 cifsdnotifyd
14231 ? 00:10:34 lighttpd
14232 ? 00:00:00 php-cgi
54981 pts/0 00:00:00 vim
55465 ? 00:00:00 php-cgi
55546 ? 00:00:00 bind9-snmp-stat
55704 pts/1 00:00:00 ps
Tra le varianti più interessanti segnaliamo la possibilità di visualizzare i primi dieci processi in base al consumo di memoria:
ps -auxf | sort -nr -k 4 | head -10
i dieci processi che consumano più CPU:
ps -auxf | sort -nr -k 3 | head -10
l'”albero” dei processi:
# ps -ejH # ps axjf # pstree
ed i thread annessi ad ognuno dei processi:
ps -AlLm
6) Comando “free”
free
free mostra lo stato di utilizzo della RAM:
total used free shared buffers cached Mem: 12302896 9739664 2563232 0 523124 5154740 -/+ buffers/cache: 4061800 8241096 Swap: 1052248 0 1052248
7) Comando “iostat”
iostat
free mostra statistiche relative a CPU, dispositivi di I/O, partizioni (usualmente denotate dal prefisso sda) e filesystem di rete.
Linux 2.6.18-128.1.14.el5 (www.keliweb.com) 09/26/2013
avg-cpu: %user %nice %system %iowait %steal %idle
3.50 0.09 0.51 0.03 0.00 95.86
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.04 31.88 512.03 16193351 260102868
sda1 0.00 0.00 0.00 2166 180
sda2 22.04 31.87 512.03 16189010 260102688
sda3 0.00 0.00 0.00 1615 0
8) Comando “sar”
sar -n DEV | more
sar abilita la reportistica di sistema e logga statistiche relative all’uso di risorse nel tempo.
Linux 2.6.18-128.1.14.el5 (www.keliweb.com) 09/26/2013 06:45:12 PM CPU %user %nice %system %iowait %steal %idle 06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78 06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52 06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78 06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22 06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19 Average: all 2.02 0.00 0.27 0.01 0.00 97.70
Se scriviamo in questo modo, invece, abilitiamo la scrittura di un file di log relativo alle ultime 24 ore del sistema, utile in caso di crash del server ad esempio:
sar -n DEV -f /var/log/sa/sa24 | more
oppure possiamo mostrare l’uso in tempo reale con queste opzioni:
sar 4 5
9) Comando “mpstat”
mpstat -P ALL
mpstat su sistemi multi-processore mostra le attività di ognuno di essi, dove il processore 0 è considerato il primo. Ad esempio:
Linux 2.6.18-128.1.14.el5 (www.keliweb.com) 09/26/2013 06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04 06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31 06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93 06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00 06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80 06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91 06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98 06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75 06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69
10) Comando “pmap”
pmap -d PID
Ad esempio:
pmap -d 12345
mostra un report annesso all’uso delle risorse da parte del processo con PID 12345:
12345: /usr/bin/php-cgi Address Kbytes Mode Offset Device Mapping 0000000000400000 2584 r-x-- 0000000000000000 008:00002 php-cgi 0000000000886000 140 rw--- 0000000000286000 008:00002 php-cgi 00000000008a9000 52 rw--- 00000000008a9000 000:00000 [ anon ] 0000000000aa8000 76 rw--- 00000000002a8000 008:00002 php-cgi 000000000f678000 1980 rw--- 000000000f678000 000:00000 [ anon ] 000000314a600000 112 r-x-- 0000000000000000 008:00002 ld-2.5.so 000000314a81b000 4 r---- 000000000001b000 008:00002 ld-2.5.so ..... ...... .. 00002af8d4b15000 4 r---- 0000000000009000 008:00002 libnss_files-2.5.so 00002af8d4b16000 4 rw--- 000000000000a000 008:00002 libnss_files-2.5.so 00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted) 00007fffc95fe000 84 rw--- 00007ffffffea000 000:00000 [ stack ] ffffffffff600000 8192 ----- 0000000000000000 000:00000 [ anon ] mapped: 933712K writeable/private: 4304K shared: 768000K
In particolare la riga finale riporta informazioni su memoria mapped, ovvero 933712K di memoria RAM utilizzata dai file, memoria writeable/private, ovvero 4304K di memoria destinati ad indirizzi privati e shared, ovvero 768000K spazio di indirizzi condiviso.
11,12) Comandi “netstat” e “ss”
I comandi in questione forniscono informazioni sui pacchetti di rete (netstat) e trovare processi nascosti che stiano accedendo al TCP/UDP (ss).
Esempi di base:
netstat
Output:
Active Internet connections Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 0 0 192.168.0.110.65231 mx.abc.comsas.http ESTABLISHED tcp4 0 0 192.168.0.110.64953 66.171.231.32.https ESTABLISHED tcp4 0 0 192.168.0.110.64952 66.171.231.32.https ESTABLISHED tcp4 0 0 192.168.0.110.64900 edge-star-shv-01.https ESTABLISHED tcp4 0 0 192.168.0.110.53234 edge-star-shv-01.https ESTABLISHED tcp4 0 0 localhost.49418 localhost.49420 ESTABLISHED tcp4 0 0 localhost.49420 localhost.49418 ESTABLISHED tcp4 0 0 192.168.0.110.49385 mil01s16-in-f21..https ESTABLISHED tcp4 0 0 192.168.0.110.49316 db3msgr5011501.g.https ESTABLISHED tcp4 0 0 192.168.0.110.49308 91.190.216.63.12350 ESTABLISHED tcp4 0 0 192.168.0.110.49277 157.55.130.150.40021 ESTABLISHED
ss
Output:
Total: 734 (kernel 904) TCP: 1415 (estab 112, closed 1259, orphaned 11, synrecv 0, timewait 1258/0), ports 566 Transport Total IP IPv6 * 904 - - RAW 0 0 0 UDP 15 12 3 TCP 156 134 22 INET 171 146 25 FRAG 0 0 0
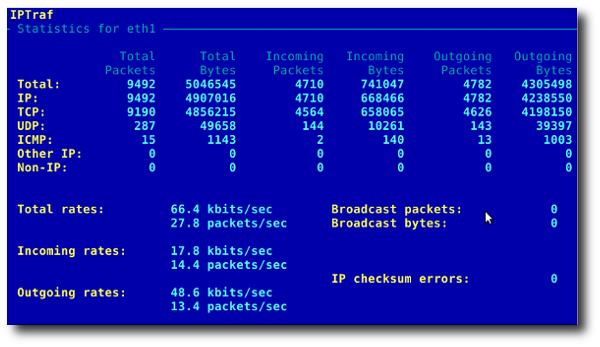
13) Comando “iptraf”
iptraf è un monitor di LAN interattivo e genera statistiche annesse ad informazioni TCP, ICMP e OSPF, ethernet, statistiche sui node, checksum IP ed altro ancora. Esso è in grado di fornire:
- statistiche sul traffico di rete per connessione TCP;
- statistiche sul traffico di rete per connessione IP;
- statistiche sul traffico per protocollo di rete;
- statistiche sul traffico di rete per porta TCP/UDP e per dimensione del pacchetto;
- statistiche sul traffico di rete per indirizzo layer2.
Un esempio di schermata di output viene mostrata di seguito.
14) Comando tcpdump
Mostra il traffico di rete in termini di pacchetti, e richiede una buona conoscenza del protocollo TCP/IP. Se ad esempio volessimo vedere informazioni sul DNS e sul traffico che riceve digitiamo nella finestra del terminale:
tcpdump -i eth1 'udp port 53'
Per mostrare invece tutti i pacchetti HTTP filtrati soltanto per i dati (e non per pacchetti SYN e FYN, ad esempio):
tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
Per visualizzare tutte le connessioni FTP aperte sull’IP 202.54.1.5:
tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20)'
similmente per quelle HTTP sull’IP 192.168.1.5:
tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
15) Comando “strace”
Questo comando viene utilizzato per tracciare call e segnali proveniente dal webserver ed è tipico in fase di debug.
16) File system proc
Altro aspetto molto utile nella fase di monitoraggio, serve a visualizzare informazioni sull’hardware in uso: di seguito si riportano i comandi, uno per riga, per monitorare CPU, informazioni sulla memoria, sulle sue zone e sui punti di mount dell’hard disk.
cat /proc/cpuinfo cat /proc/meminfo cat /proc/zoneinfo cat /proc/mounts
17) Utilizzare nagios
Si tratta di una soluzione open source per il monitoraggio del sistema (con una community molto attiva online), la quale permette di tenere sotto controllo host, rete e servizi attivi. Permette inoltre di inviare una alert nel momento in cui qualcosa non funzioni correttamente, oppure abbia ripreso a funzionare. Disponibile nella versione automatizzata ed estesa di nome FAN (Fully Automated Nagios).
18) Utilizzare Cacti
Se il terminale è complesso da utilizzare potete ricorrere ad una soluzione web-based di nome Cacti: per maggiori informazioni è possibile seguire le istruzioni reperibile sul sito ufficiale.
19 e 20) Utilizzare KDE System Guard e Gnome System Monitor
Similmente ai casi precedenti si tratta in entrambi i casi di un’utility per facilitare la gestione del sistema operativo, capace di controllare anche intere server farm. La seconda è particolarmente indicata per i principianti, mentre la prima è leggermente più complete ed altrettanto complessa.
Un commento